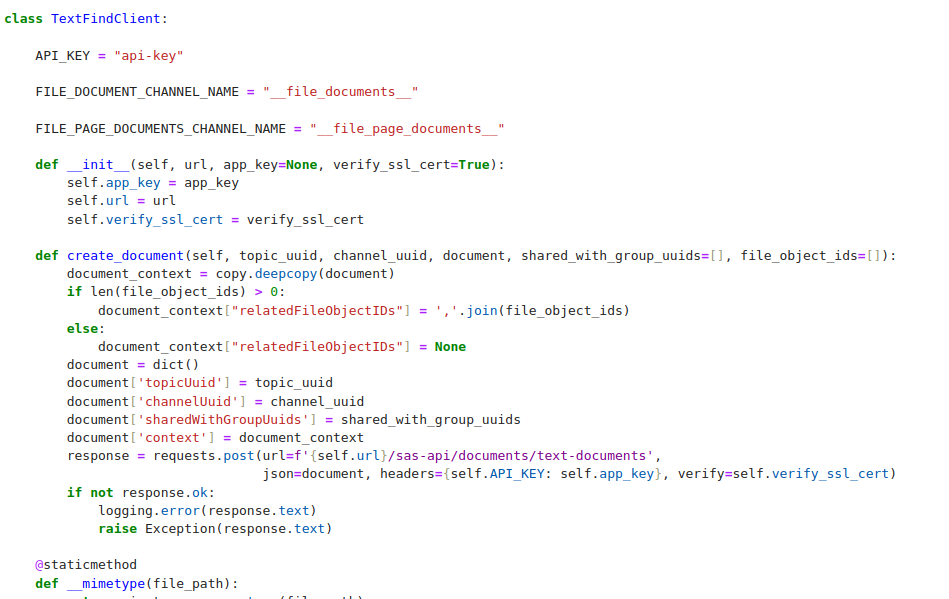
In this post you can find all you need to programmatically extract text from pdf files and import them to TextFind.
Once you’ve imported them you can run some semantic queries and post some questions, and see how TextFind will find your answers.
You can also see what configurations you need to provide in the TextFind dashboard, so you can have channels defined for your pdf content.
If you want to give it a try, then all you need access to a TextFind instance and an API KEY, so you can programmatically interact with the app.
The code is made available here on GitHub
There is a short video here showing you how this all works.
If you have any questions, like what you can do with TextFind, or you have some ideas of some apps and you would like to contribute, or support TextFind in any way please drop us a line here.
Cheers